


Impact van MS Fabric op de Azure Data Platform referentiearchitectuur
Oude wijn in nieuwe zakken!? NEE! De komst van Microsoft Fabric is vernieuwend en biedt vele nieuwe mogelijkheden voor data en analytics en voor de gerelateerde Data Platform architectuur.
Vóór de komst van Microsoft Fabric maakten wij (Powerdobs) gebruik van een drietal referentie architecturen bij het realiseren van een analytics toepassing. Zo’n referentie architectuur gebruiken we als start voor een klantimplementatie. Afhankelijk van de situatie en de wensen van de klant breiden we de architectuur uit tot een goed en passend platform waarmee de rapportage en analytics wensen van de klant worden ingevuld.
De introductie van MS Fabric is echter zo’n grote verandering in het Microsoft BI landschap dat onze referentie architecturen hierop aangepast zijn. In deze blog gaan we hier dieper op in.
Grofweg onderkennen we nu de volgende 4 referentie architecturen voor een Microsoft Analytics toepassing:
- Powerdobs Microcloud – Power BI only
- Powerdobs Azure Synapse Analytics
- Powerdobs Microsoft Fabric
- Powerdobs Azure Databricks empowered Analytics
Medaille gedachtengoed – Brons, Zilver, Goud
Voordat we de 4 referentie architecturen tegen het licht houden, ga ik eerst nog even in op de medaille aanpak die centraal staat in elk van de bovengenoemde architecturen. Deze methode gaat er vanuit dat:
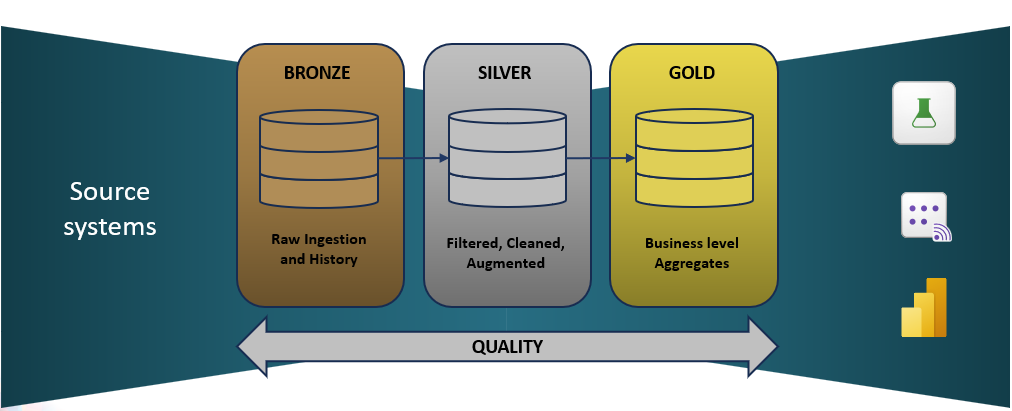
- Data vanuit een bronsysteem 1 op 1 gekopieerd wordt naar het data platform in de BRONZEN-laag.
- Vervolgens wordt het opgewerkt en geharmoniseerd in de ZILVEREN-laag.
- Uiteindelijk wordt het ‘rapportage klaar’ gemaakt in de GOUDEN-laag.
Meer over deze medaille aanpak kun je lezen in deze blog.
Powerdobs Micro Cloud – Power BI Only
De meest eenvoudige analytics referentie architectuur van Powerdobs is de Micro Cloud. Deze architectuur biedt klanten een volwaardige Analytics omgeving die in een korte tijd gerealiseerd kan worden zonder Azure subscription.
Natuurlijk zitten er beperkingen aan deze architectuur omdat er geen data platform gebruikt wordt. Maar zolang het aantal bronsystemen, de hoeveelheid data en de behoefte aan historische rapportages beperkt is, biedt deze architectuur voldoende mogelijkheden.
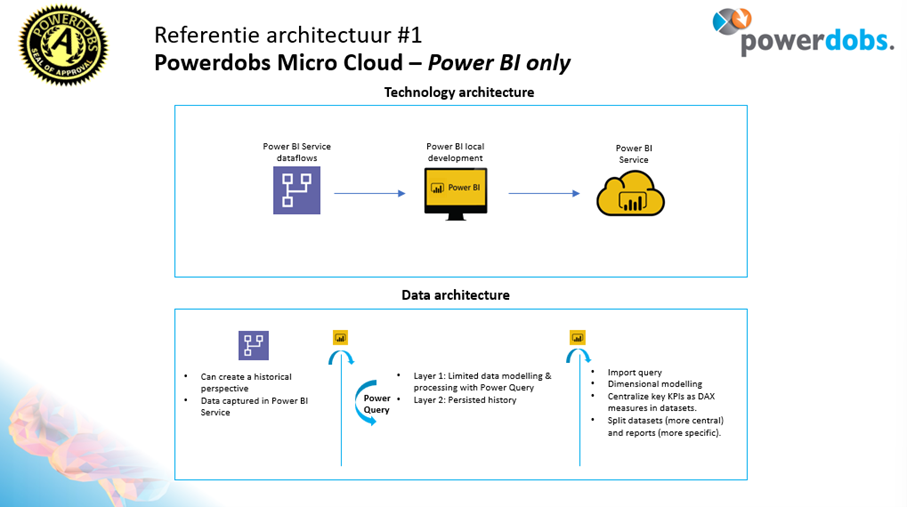
Door middel van een dataflow in Power BI worden de bronzen- en zilveren laag in één stap aangemaakt. Denk als voorbeeld aan een auto dealer bedrijf dat data uit verschillende dealersystemen samen wil brengen in zijn rapportages. Met de dataflows wordt dan data van verschillende auto‘s opgehaald, uniform gemaakt en aan elkaar geknoopt. Zo ontstaat de bronzen- en zilveren laag.
Vervolgens wordt in de Power BI dataset de business logica en de berekeningen toegevoegd. Met DAX Measures geven we de indicator mee, die weergeeft of een auto langer dan 30 dagen op voorraad staat en wordt de marge berekent. Zo ontstaat de gouden laag.
De data uit de gouden laag wordt in de Power BI rapporten mooi gevisualiseerd en daarmee is het klaar om aan eindgebruikers te tonen.
De architectuur is eenvoudig en tegen een geringe investering in te richten. Voor meer details zie ook deze blog: Micro Cloud blog.
Powerdobs Azure Synapse Analytics
Met de tweede referentie architectuur van Powerdobs trekken we de toolbox van het Azure Data Platform open waarin we de bronzen, zilveren en gouden laag gaan opbouwen. Daarmee komt in Power BI echt de nadruk te liggen op het visualiseren van de data, de complexere dataverwerking doen we in het Azure Data Platform.
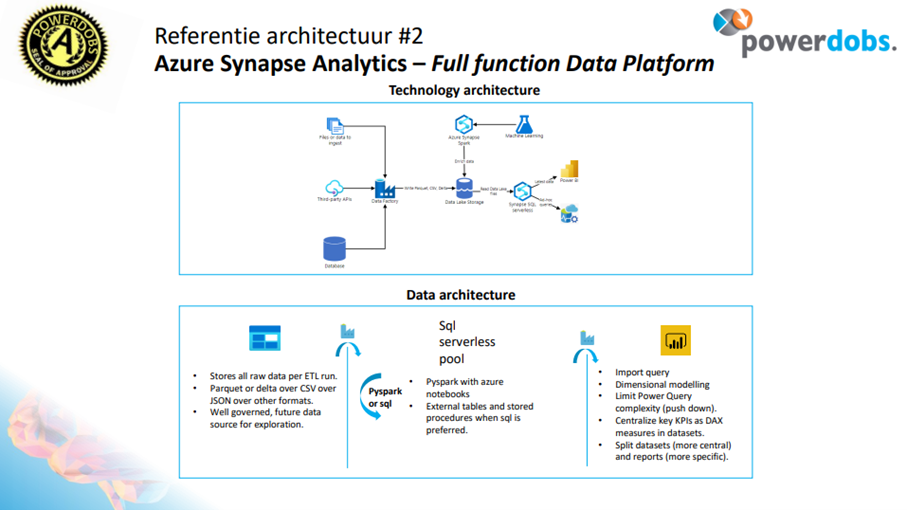
Om de bronzen laag op te bouwen wordt data, meestal uit verschillende bronsystemen, één op één gekopieerd van de bron naar het Data Lake (de eerste opslaglocatie in het data platform). Hiervoor gebruiken we Azure Datafactory (ADF), ADF haalt de data uit de bronnen, zet het om naar het ‘Delta Parquet formaat’ en legt het vast in het data lake als bronzen laag. In deze stap kan een historische laag aangemaakt worden. Hiermee kan de stand van de data op een bepaalde dag in het verleden bekeken worden.
Om te komen tot de zilveren laag gaan we de data opwerken en verrijken. Om in het voorbeeld van de auto dealers te blijven, voegen we de data van Toyota en Lexus toe. We koppelen de data van de auto’s en maken hem uniform en netjes. Dit doen we met Azure notebooks.
Aan deze data uit de zilveren laag voegen we businesslogica en berekeningen toe middels Synapse SQL serverless views. Denk aan de indicator voor een auto die langer dan 30 dagen op voorraad staat of de berekening van de marge op een verkochte auto. Zo ontstaat de gouden laag. De data uit de serverless views wordt middels Power BI datasets klaargemaakt om in Power BI gevisualiseerd te worden.
Wat deze architectuur extra aantrekkelijk maakt is dat zowel de zilveren als de gouden laag virtueel kunnen worden gemaakt, de data wordt dus niet fysiek opgeslagen. Hierdoor kan nieuwe functionaliteit heel snel beschikbaar gemaakt worden in de Power BI rapporten. Mocht eventueel blijken dat de performance van de rapporten achteruit gaat dan kan er alsnog gekozen worden om de data fysiek op te slaan.
Deze architectuur is geschikt voor klanten met verschillende bronsystemen en grotere hoeveelheden data. De architectuur is geavanceerder en is beter af te stemmen op meerdere bronsystemen. Ook biedt Azure nog vele extra tools waarmee je de architectuur voor specifieke toepassingen kunt uitbreiden. Denk bijvoorbeeld aan streaming data of data science toepassingen.
Powerdobs Microsoft Fabric
Met de introductie van Microsoft Fabric heeft Microsoft de hierboven beschreven architectuur meer toegankelijk gemaakt en tevens uitgebreid met het geniale concept van ‘One Lake’. Voor veel bedrijven zal het dus een no-brainer worden om deze optie te kiezen.
Door in Power BI het ‘MS Fabric’ vinkje aan te klikken heb je direct een volledig Azure Data Platform tot je beschikking en de maandelijkse Azure kosten zijn daarmee ook nog eens heel goed te voorspellen. Echt een hele grote stap vooruit dus!
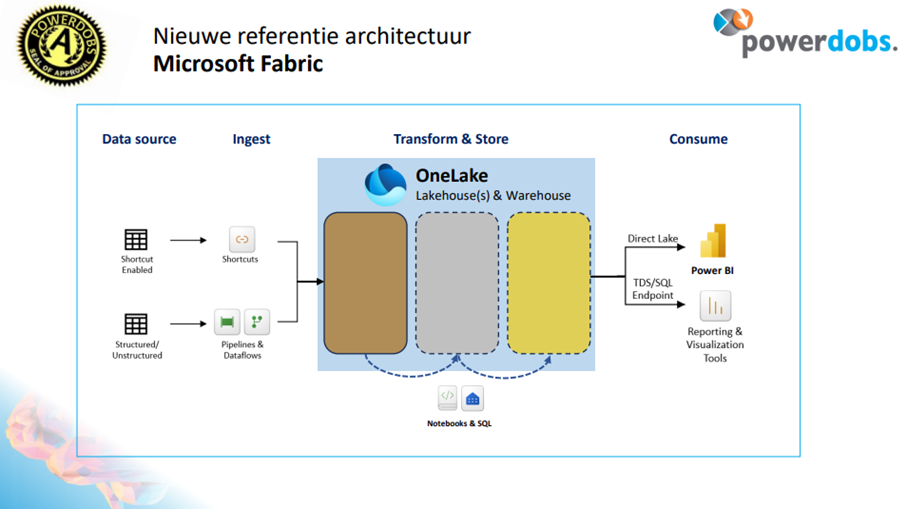
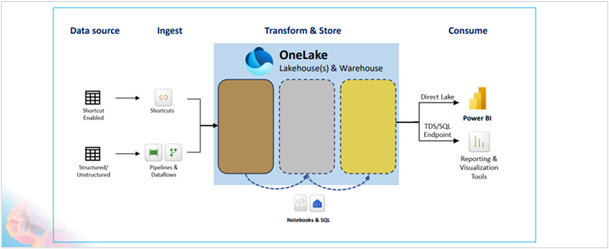
Data wordt één op één gekopieerd van de bron naar One Lake, hier wordt de data in Delta Parguet format opgeslagen. Voor deze kopieerslag maken we gebruik van Pipelines (uit ADF) en/of Dataflows (uit Power BI). Zo ontstaat de bronzen laag.
Vervolgens wordt de data middels Notebooks en of Dataflows getransformeerd van brons naar zilver en naar goud. Het is mogelijk om hiervoor een tool naar keuze te gebruiken, Dataflows of Notebooks met PySpark, SQL of Scala. Daarmee staat de data dan helemaal klaar voor de rapportages in Power BI. En, een extra bijkomend voordeel is dat Power BI nu ook direct kan inprikken op One Lake en dat de data dus niet verplaatst hoeft te worden naar Power BI. Zie onze blog over direct lake mode.
Deze architectuur is zowel geschikt voor klanten met veel als met weinig bronnen en data. De reden is dat Fabric enorm schaalbaar is en de instapkosten laag zijn.

De grootste verbeteringen van Fabric ten opzichte van een klassiek Data Platform met Azure Synapse Analytics zijn:
- Alle onderdelen van het data platform zijn beschikbaar in een applicatie.
- Er is maar één compute resource nodig voor Fabric waar alle onderliggende services gebruik van maken.
- Door One Lake is minder duplicatie van data nodig.
- Direct Lake modus in Power BI zorgt ervoor dat Power BI rechtstreeks gebruik kan maken van bronbestanden in One Lake.
- Omdat bestanden in het One Lake de open standaard Delta Parquet gebruiken zijn deze bestanden ook te gebruiken in services van Google, Amazon, Snowflake en Databricks.
- Er zijn geen ingewikkelde infrastructuur en security instellingen meer nodig omdat alle services binnen Fabric werken.
- Power BI Git integratie zorgt ervoor dat versiebeheer ook voor Power BI beschikbaar is.
- De kosten zijn voorspelbaarder omdat er maar een compute resource aangeschaft hoeft te worden in plaats van een resource voor iedere service uit het Azure Platform.
En, mocht de behoefte ontstaan om ‘buiten de MS Fabric’ omgeving extra Azure tools te gebruiken dan kan dat ook nog altijd.
Powerdobs Azure Databricks empowered Analytics
Naast de hierboven beschreven referentie architecturen werken we ook regelmatig met een Azure Databricks architectuur. Functioneel gezien is de architectuur vergelijkbaar met de hierboven beschreven Fabric en Synapse oplossingen. Databricks is een Microsoft partner product dat behalve op Azure ook op andere grote platformen draait.
De keuze tussen de platforms zal afhangen van specifieke behoeften en prioriteiten. Databricks, is code first, Synapse en MS Fabric bieden meer visuele mogelijkheden. Qua performance loopt Databricks nog wat voor, ben je dus op zoek bent naar een superkrachtige machine learning-tool en wil je deze gebruiken voor enorme hoeveelheden data, dan is Databricks de beste optie. Gezien het feit dat Microsoft veel mankracht in Synapse en MS Fabric steekt verwacht ik dat ze deze achterstand wel gaan dicht lopen.
De verschillen tussen de twee zijn verder relatief klein. Voor meer details verwijs ik je graag naar onze blog over Azure Databricks.
Mocht je vragen of opmerkingen hebben over het bovenstaande, schroom dan niet om contact met ons te zoeken.
