


Power BI Direct Lake Mode – this is what we’ve been waiting for!
What is ‘Direct Lake Mode’?
With the introduction of Fabric and OneLake Microsoft also introduced a complete new way for Power BI to analyse large volumes of data. This is supported through the ‘Direct Lake Mode’. Before Fabric there were 2 ways to analyse data in Power BI, these are the DirectQuery and Import modes. To better understand how Direct Lake mode works we need to understand how Import and DirectQuery work and how the DAX queries are handled by each storage mode to provide the resulting visuals:
- DirectQuery
When a user interacts with a report, DirectQuery translates DAX queries into native SQL and sends these queries to the database directly. The SQL queries are run against the database and the resulting data is then sent back to Power BI and used to render visuals. The benefit of this is of course that the latest data is always available, but at reduced performance. - Import mode
When a user interacts with a report, only the specific data requested by the queries are loaded and returned to the visual. This is because the data is routinely imported into the model, compressed with the Vertipaq engine and stored in columnar format in Power BI. The benefit of this is blazing fast query performance, but the data will only be as recent as the last import.
In our blog post Power BI Storage Modes explained we discussed these modes in more detail.
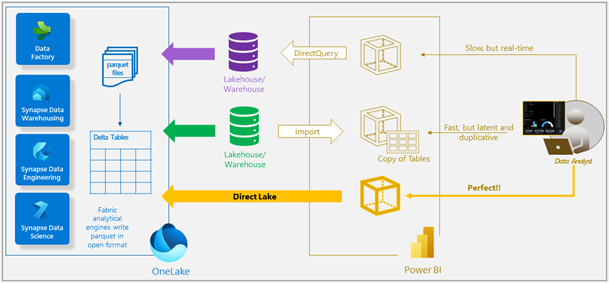
Now, imagine combining the query performance of Import mode with the low data latency of DirectQuery. This is where Direct Lake makes its entrance, offering the best of both worlds. With Direct Lake mode you can analyze extremely large data volumes while benefiting from exceptional query performance and minimal data latency. It represents a remarkable fusion of DirectQuery and Import mode, unleashing the full potential of Power BI.
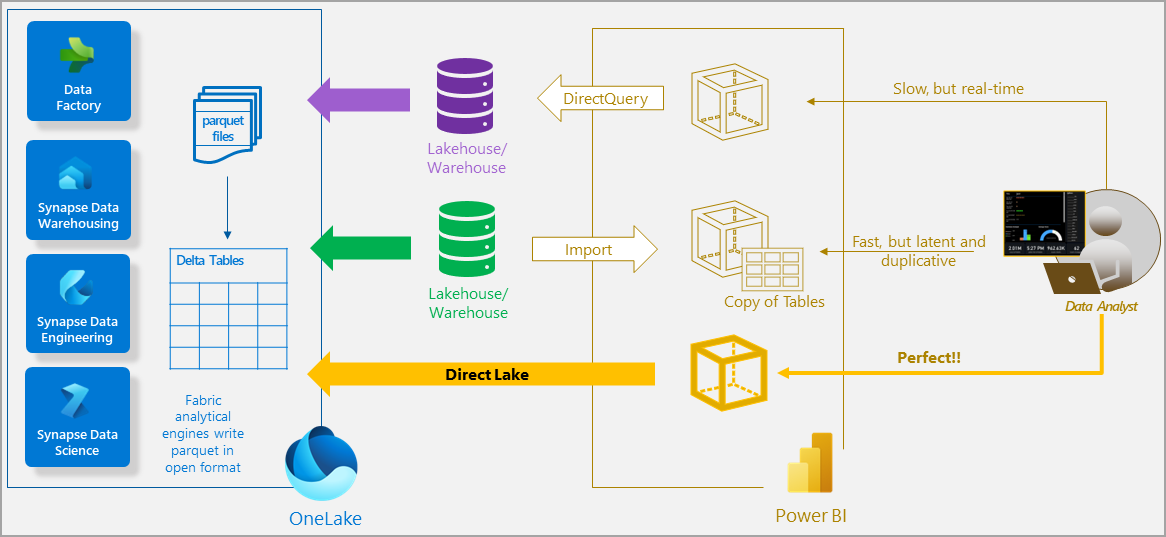
Picture from Microsoft documentation

How does it work?
Direct Lake achieves this by making use of a Lakehouse and delta tables. The delta tables are stored as parquet files which is also a columnar format. This means that when a user interacts with a report the vertiscan queries can be sent directly to the delta tables and the columns required by the query can then be loaded into memory, similar to import mode. The delta tables use a different compression than vertipaq, which also means that as the data is fetched it can be transcoded on the fly.
By loading the data directly from a Lakehouse in OneLake the import requirement is eliminated and so is the need for translation to other query languages or query execution on additional database systems. Because there is no import process, changes in the data source are reflected in Power BI as they happen without the need to wait for a refresh. This provides a real-time view of the data and makes Direct Lake an ideal choice when working with very large dataset with frequent data updates.
But, the innovation does not stop there! As an extra optimization Microsoft introduced the ability to order the data in the parquet files using the v-order algorithm. This allows for higher compression and querying speed.
Prerequisites
It is important to note that Direct Lake is available on Power BI Premium Per Capacity and Microsoft Fabric F SKU’s. Unfortunately Direct Lake will not be available on Power BI Pro, Power BI Premium Per User or Power BI Embedded A/EM SKUs at this moment.
Additionally a Lakehouse with one or more delta tables (hosted on a supported Power BI or Microsoft Fabric capacity) is also a prerequisite as this provides the storage location for the parquet-formatted files in OneLake as well as the access point to launch the Web modeling for the creation of a Direct Lake dataset.
Known issues and limitations
I start with an extra disclamer: Direct Lake is currently in preview and as such these limitations could change before it reaches General Availability. However, currently we know the following issues and limitations:
- Power BI Desktop does not yet support generation of Direct Lake datasets, this needs to be done in the Web modeling experience integrated into Lakehouse.
- Calculated columns and calculated tables are not yet supported.
- Some data types may not be supported.
- Only Single Sign-On (SSO) is supported.
- Query limits set in the tenant ad the dataset size per SKU will still be applicable.
- RLS is not currently supported.
- Calculation groups not currently supported.
- Embedded scenarios that rely on service principles are not yet supported.
What’s next?
Direct Lake storage mode is an improvement on two existing storage modes, Import and DirectQuery. This does not mean that Direct Lake replaces these storage modes. It does however present a new way to store data using Fabric. Delta tables can even be used with Import or DirectQuery mode using the Lakehouse SQL Endpoint.
It is clear though, that Direct Lake is the perfect storage mode that we have been waiting for and that it will bring lots of new possibilities for data analysis in Power BI. Get ready for unparalleled performance, real-time insights, and the ability to tackle even the most massive datasets with ease.
If you have questions or you want to see the Direct Lake Mode in action, don’t hesitate to contact us!
Further reading: