



Is Azure Databricks an alternative for Synapse or MS Fabric?
Databricks is an industry-leading, cloud-based data engineering tool used for processing and transforming massive quantities of data and exploring the data through machine learning models. It allows organizations to easily achieve the full potential of combining their data, ELT processes, and machine learning.
Similar to ‘the regular Azure Data Platform’ with components like ADF and Synapse, it helps organizations build a single, continuous data system instead of managing multiple data architectures simultaneously. In addition, Databricks uses Delta Lake architecture, an open-source storage format, to confer data governance, reliability, and ACID-compliance transactions on a data lake.
Databricks also provides a SaaS layer in the cloud which helps the data engineers, data analysts and data scientists to autonomously provision the tools and environments that they require to provide valuable insights.

What is cool about Databricks?
In the past data scientists and data engineers were forced to use various loosely coupled tools to handle and manipulate their data. The big advantage of integrated platforms like Databricks, but also the Azure Data Platform and MS Fabric, is that all required tools are available at your fingertips and they are fully integrated. Other things that are cool about Databricks:
- Databricks compresses data from the unified Spark engine which uses higher-level libraries and supports data streaming, graph processing, SQL queries, and machine learning. It removes the complexity involved in handling such processes and making it more seamless for the productivity of developers.
- Users have found the SQL in Databricks to be user-friendly, allowing them to easily write and execute queries. Praising the intuitive nature of the SQL interface, making it accessible for users of different skill levels.
- The multilevel data security of Databricks is another benefit that is inherent in the platform, which has options for adjusting access whether for identity management, fine-grained or role-based controls.
- The ultimate feature: Databricks includes cost optimization. this helps you by keeping a proper check and control over your data expenses. It gives you the power to auto-terminate unwanted expenses and set your optimization budget.
- Last but not least Databricks can be integrated with Microsoft Fabric and with other Azure Data Platform component making it an heterogeneous platform possible.
Compared to ‘the regular Azure Data Platform’ and MS Fabric there are 2 main differences. First of all Databricks has a code first approach where-as Azure has more drag and drop functionality. Most experienced data engineers will prefer the code first approach, for maintainability and readability. Next to that Databricks is currently the main contributor of new developments for the spark clusters resulting in it being ahead of its Microsoft counterparts when supporting the latest versions. Therefor the performance of Databricks is still somewhat better. It is fair to assume though that Microsoft will catch up soon.
In this blog I mainly focus on Databricks and Synapse, it is fair to assume though that the pros and cons of Synapse are valid for MS Fabric as well as Microsoft is putting tremendous efforts into MS Fabric.
Less cool about Databricks
Databricks’ pitfalls are not as obvious as its benefits, but users tend to face the following challenges.
- Databricks has a steep learning curve and requires a significant amount of time and effort to set up and configure.
- It primarily uses python, which can be challenging for users who are not familiar with the language.
- Can be expensive. Storage, networking, and related costs will vary depending on the services you choose and your cloud service provider.
- Databricks has a smaller community compared to ‘the regular Azure Data Platform’, which can make it difficult to find answers to specific questions.
- Some users have experienced random task failures while using the platform, making it challenging for them to debug and profile code effectively. These unexpected failures undermine confidence in the system’s stability and result in delays as users attempt to identify and fix these issues.
As these pitfalls may still be true it is fair to say though that the user base of Databricks is growing and that Databricks is a professional organisation focused on fixing possible technical issues.
Azure Synapse vs. Databricks Comparison
Azure Synapse combines enterprise data warehousing, big data processing with Apache Spark, and tools for BI and machine learning. Just like Databricks it’s an end-to-end analytics solution. There are difference though.
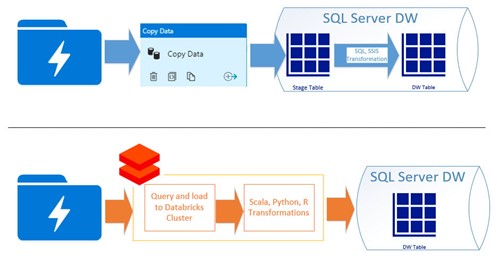
While Azure Synapse is used for Data Integration Services to monitor data movements from various sources at scale, Databricks’ edge is to simplify Data Architecture by unifying Data, Analytics, and AI workloads in a single platform. Some more differences are mentioned below.

Processing & Performance
Synapse is a Data Integration service to perform ETL processes and orchestrate data movements at scale. Contains open-source Spark and built-in support used for performing big data analytics and ML tasks. Apache Spark powers both Synapse and Databricks. While the Synapse has an open-source Spark version, the databricks has an optimized Spark offering 50 times increased performance. With optimized Apache Spark support, Databricks allows users to select GPU-enabled clusters that do faster data processing and have higher data concurrency.
Ease of Usage
Synapse has an easy-to-use interface suitable for users familiar with SQL and data analysis. There is little need for configuration and setups. Databricks uses a lot of open-source ML libraries and requires familiarity with Apache tools. It is geared towards a more technical audience with experience managing clusters and configuration updates.
Flexibility in Coding
Synapse makes use of ETL pipeline process using GUI tools, developers have less flexibility as they cannot modify backend code. Databricks implements a programmatic approach that provides the flexibility of fine-tuning codes to optimize performance.
Unity Catalog
Unity Catalog is a fine-grained governance solution for data and AI on the Databricks platform. It helps simplify security and governance of your data by providing a central place to administer and audit data access. Delta Sharing is a secure data sharing platform that lets you share data in Azure Databricks with users outside your organization. It uses Unity Catalog to manage and audit sharing behaviour.
Integrations
Synapse comes with Azure tools for governance, Data Factory for ETL movements, and Power BI for analytics. Additionally, it works with Spark in Spark pools to run notebooks. Databricks provides integrations with ETL/ELT tools like Azure Data Factory, as well as data pipeline orchestration tools like Airflow and SQL database tools like DataGrip, SQL Workbench.
Pricing
The pricing of Azure Synapse is more complex because it is charged based on data exploration, data warehousing, storage options such as the number of TBs stored and processed, data movement, runtime, and cores used in data flow execution and debugging. When it comes to Databricks pricing, it’s based on your compute usage. Storage, networking, and related costs will vary depending on the services you choose and your cloud service provider.
Choosing Between Databricks and Synapse: Which One Is Right for You?
The choice between these two platforms will depend on your specific needs and priorities. Databricks uses scripts to integrate or execute machine learning models. This makes it simple to feed a dataset into a machine learning model and then use Databricks to render a prediction. Then you can output the results of that prediction into a table in SQL Server.
Given the fact it appears Microsoft is putting a lot of manpower into Synapse and investing its resources into it, I would say it is worth using the tool especially if you are already using parts of Synapse, it will allow you to simplify the architecture. If you are looking for a super powerful machine learning tool and plan on putting it to use on a huge amount of data, then Databricks would be the best option. I feel the differences between the two are relatively small most of the time and it just depends on what the requirements and needs of the company are.
Reference links:
- https://www.databricks.com/discover/data-lakes/challenges
- https://www.databricks.com/
- https://learn.microsoft.com/en-us/answers/questions/858790/azure-databricks-vs-adf
- https://stackoverflow.com/questions/71259455/data-factory-synapse-analytics-and-databricks-comparison