



Microsoft Fabric, the best thing since sliced bread!
De grootste aankondiging tijdens de afgelopen Microsoft Build conferentie is voor ons als data liefhebbers, zonder twijfel Microsoft Fabric. Van veel klanten krijgen we echter de vraag: Wat is het nou eigenlijk precies en wat kunnen en moeten we er mee? In mijn vorige blog, Microsoft Build – de belangrijkste takeaways, heb ik al een tipje van de sluier opgelicht. Hieronder volgen meer details!
Samenvattend bestrijkt Fabric het volledige spectrum van diensten, van dataverplaatsing, datalake, data-engineering, data-integratie en data science, real-time analytics en business intelligence. Het is een end-to-end data analytics platform gebaseerd op de volgende pijlers:
- Compleet analyseplatform
- Lake-Centric en Open
- Empowerment van de eindgebruikers
- AI Powered
In de onderstaande plaat staan de componenten van Microsoft Fabric mooi visueel gerangschikt. Zoals je ziet kunnen de ‘traditionele gebruikers’ als Data Engineers, Power BI experts en eindgebruikers allemaal hun hart ophalen met dit platform.
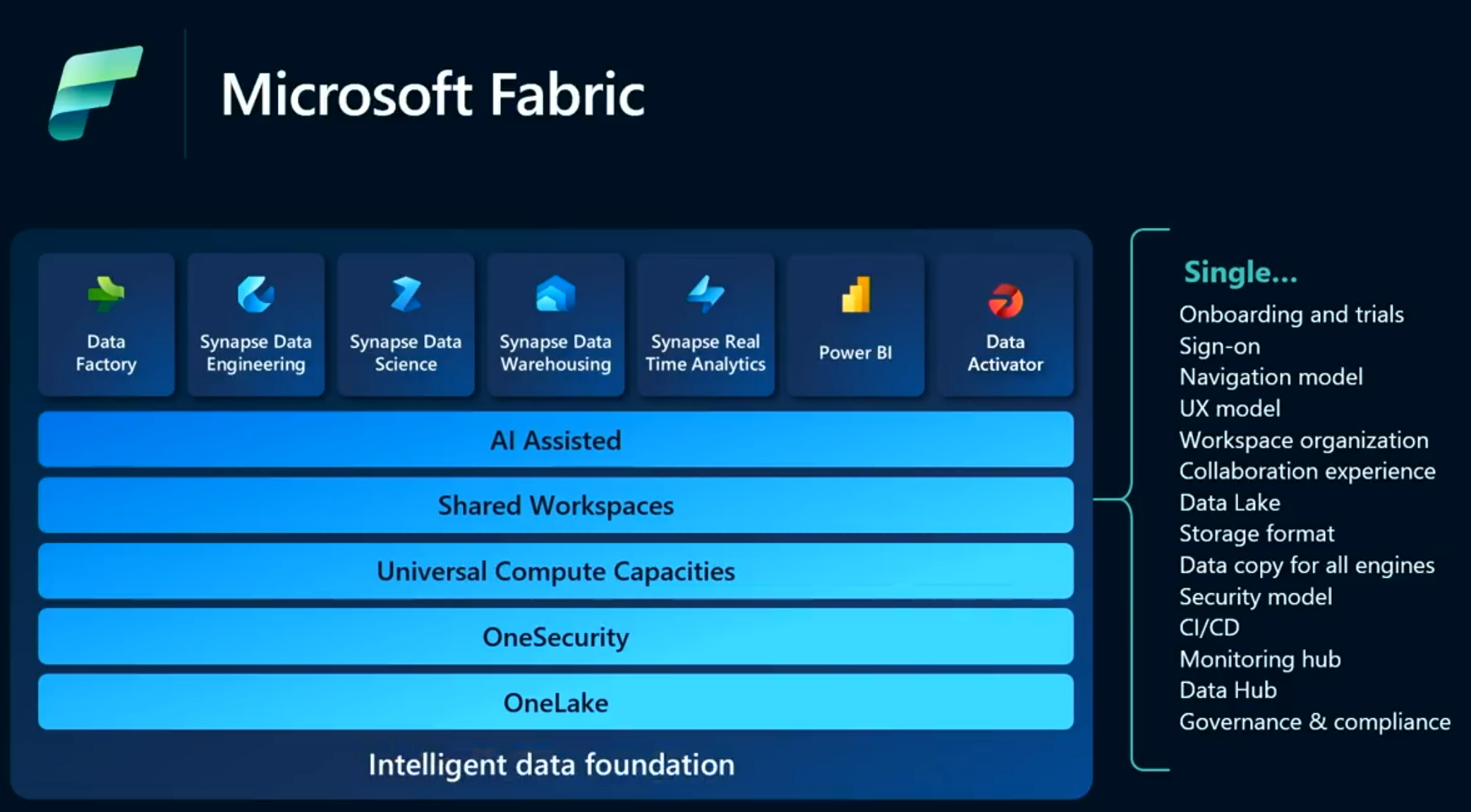
Met deze componenten samen in één platform zie ik de volgende voordelen:
- OneLake biedt de mogelijkheid voor klanten om slechts één gegevens kopie vast te leggen terwijl ze deze dataset met verschillende analysetools kunnen benaderen. Microsoft noemt het niet voor niets de “OneDrive voor gegevens”.
- Een brede set met goed geïntegreerde data analytics tools.
- Een gedeelde omgeving voor de verschillende tools die vertrouwd en gemakkelijk te leren is.
- Gemakkelijk hergebruik van componenten en oplossingen door alle ontwikkelaars.
- Gecentraliseerde administratie en governance.
Tot 1 juli is Fabric standaard uitgeschakeld en moet je het dus handmatig inschakelen om het te kunnen gebruiken! Na 1 juli kun je automatisch helemaal los gaan met Fabric. De nieuwe Fabric- (en Power BI-) startpagina, ziet er als volgt uit:
 |
| Fabric home page |
 |
| Fabric workload switcher |
Los van het feit dat diverse producten nu worden gegroepeerd onder de Fabric paraplu blijven de producten ook separaat bruikbaar. Microsoft stelt dat ‘standalone PaaS-producten onaangeroerd blijven en actief blijven’. Bestaande klanten hoeven zich dus geen zorgen te maken over oplossingen die momenteel in productie zijn.
“Existing Microsoft products such as Azure Synapse Analytics, Azure Data Factory, and Azure Data Explorer will continue to provide a robust, enterprise-grade platform as a service (PaaS) solution for data analytics. Fabric represents an evolution of those offerings in the form of a simplified SaaS solution that can connect to existing PaaS offerings. Customers will be able to upgrade from their current products into Fabric at their own pace.” by Arun Ulag, Corporate Vice President Azure Data
Daarnaast wijst alles er op dat er goede mogelijkheden gaan komen voor bestaande klanten om te migreren van de bestaande omgeving naar de nieuwe SaaS-oplossing (Fabric). Een ‘vertaaltabel’ is al gemaakt! Als je bekend bent met het huidige Synapse-aanbod dan biedt de onderstaande referentietabel wat extra houvast:
| Synapse | Fabric |
|---|---|
| ADLS Gen2 | OneLake |
| Azure Data Explorer (ADX/Kusto) | Real-time Analytics |
| CI/CD, Git | ALM |
| Data Flows | Dataflows |
| Datasets | Sources/Destinations |
| Linked Services | Connections |
| Notebooks | Notebooks |
| Pipelines | Data Pipelines |
| Self-Hosted Integration Runtime (SHIR) | Power BI Gateway |
| Spark | Spark |
| SQL Pools | Data Warehouse |
| SQL Serverless | Lakehouse |
| Synapse Workspace | Power BI Workspace |
Hoewel Fabric nog steeds in preview is, zou ik je willen aanmoedigen om functies uit te proberen en nu alvast naar goede use cases te kijken. Belangrijkste reden hiervoor is dat Fabric echt ‘de toekomstige richting’ van Microsoft is als het gaat om Data Analytics. Daarnaast kun je direct gebruik gaan maken van de volgende voordelen:
- Fabric is gebaseerd op het ‘serverless paradigma’. Je hoeft dus geen clusters meer te starten of resources in Azure te configureren. In plaats daarvan levert Fabric capaciteit als een SaaS-resource. Je kunt nu dus veel sneller en gemakkelijker je nieuwe Analytics omgeving opstarten.
- OneLake maakt het gemakkelijker om:
- Grote hoeveelheden gegevens op te slaan.
- Één eenduidige, gecertificeerde en real-time bron van waarheid vast te leggen.
- Bestaande gegevens uit Azure, AWS of OneLake te gebruiken via shortcuts of mounts.
- Data analisten kunnen nog steeds aan de gang met skills als SQL, Spark of DAX.
- Performance voordelen: Microsoft werkt aan diverse performance verbeteringen. Één voorbeeld is Direct Lake, de nieuwe opslagmodus voor Power BI. Alles in OneLake wordt nu opgeslagen in hetzelfde open Delta Parquet-formaat.
- Vereenvoudigde facturering en beheer van runtime-componenten:
- Fabric biedt nu ‘capacities with compute’ in plaats van activiteiten per pijplijn of TeraBytes/s. Dit betekent dat de berekening en afhankelijkheden gesimplificeerd worden.
- In plaats van elke resource afzonderlijk te beheren en te pauzeren wanneer je hem niet nodig hebt, kun je nu ‘Fabric compute capacity’ activeren. Deze beginnen bij een veel lagere prijs dan een Power BI Premium-capaciteit. Exacte prijzen worden later bekend gemaakt.
- AI wordt een belangrijker onderdeel van ons dagelijks werk, met de integratie van Copilot in Microsoft Fabric en Power BI. Ik verwacht niet dat het werk van de Power BI ontwikkelaars daarmee volledig weg geautomatiseerd wordt, maar het gaat ons werk zeker gemakkelijker en anders maken doordat we nu mogelijkheden krijgen om:
- Code en query’s automatisch te laten genereren.
- Normale tekst te laten transformeren naar dataflows en datapipelines.
- Binnen enkele seconden een Power BI rapport te laten genereren.
- DAX code te genereren.
- Automatisch genereren van narrative summaries.
Next steps?
Microsoft Fabric lijkt dus echt heel veel moois en extra’s te gaan bieden voor de data en analytics community! Er zijn echter ook nog heel wat vragen die in de nabije toekomst beantwoord zullen gaan worden. Ik denk daarbij aan vragen als:
- Is de performance van Direct Lake echt zo goed als nu wordt geschetst?
- Wat is de V-order met betrekking tot parquet files en hoe kunnen we dat beïnvloeden/afhandelen?
- Hoe houdt de Fabric capaciteit stand bij specifieke workloads? Het wordt interessant om te zien wat bijvoorbeeld een laagste capaciteit aankan, en hoe bruikbaar dit instapniveau in de praktijk blijkt te zijn.
Op Microsoft Learn zijn er al 4 End-to-end tutorials beschikbaar om je op weg te helpen met het leren van Fabric:
- Lakehouse
- Data Science
- Real-Time Analytics
- Data Warehouse
Maar ook over meer ervaringsspecifieke onderwerpen als Power BI, Data Factory and Price prediction with R for Data Science is al veel kennis voorhanden.
Ik hoor je denken: “Dus nu moet ik al die nieuwe producten/diensten leren met alle bijbehorende talen, zoals T-SQL, Python, R, KQL enzovoort enzovoort…?” Als je de kennis al hebt of je hebt de ambitie om het te leren!? Natuurlijk, dat is top! Maar ik vind het zeker geen noodzaak om alles te weten. Ook in de wereld van Fabric gaan we T-shaped specialisten zien op de verschillende onderdelen.
Ik ben erg enthousiast over deze volgende stap voorwaarts van Microsoft en ik sta te popelen om meer van Fabric te leren. En ook om de use cases die bij onze klanten spelen met beide handen aan te pakken!