



Mapping Dataflows: nieuwe tool, nieuwe standaard??
Mapping Dataflows zijn sinds Oktober 2019 Generally Available in Azure Data Factory. Ook zijn ze later toegevoegd aan Synapse Analytics. Mapping Dataflows (MDFs) biedt gebruikers een visuele interface om data Extract, Transform en Load activiteiten uit te voeren op Spark Clusters. In dit blog gaan we in op de valkuilen en tips voor data engineers rondom MDFs! Dat doen we door twee veel voorkomende toepassingen van MDFs door te nemen: (1) toepassing in een SQL Datawarehouse context, bijvoorbeeld Synapse dedicated SQL-pools, en (2) toepassing in een Data lake(house) context, bijvoorbeeld Databricks en Delta Lake.
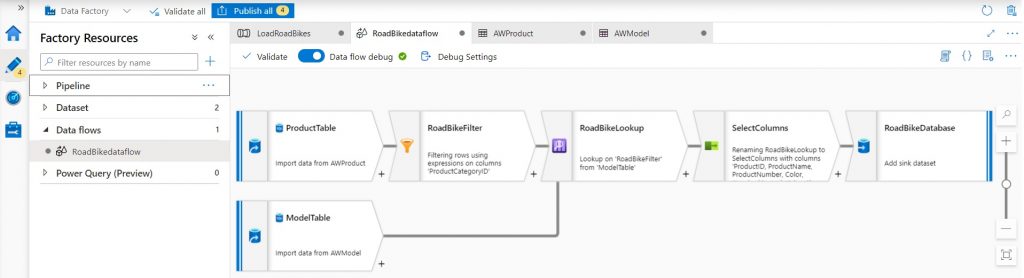
Algemene observaties
- Het visuele karakter van MDFs kan een voordeel zijn als het gaat om het snel doorgronden van ETL jobs, zeker voor minder ervaren data engineers of data engineers die gewend zijn om met visuele ETL tools te werken in plaats van met SQL-code. Voor die groep geldt: Als je een ETL-job overneemt van een collega zal je blij zijn dat het om een MDF gaat! Tip: comments in MDFs kan alleen in de naam van transformatiestappen, de omschrijving van de gehele dataflow, en in de expression builder. Doe dat ook, want je kan als developer nog niet op andere plaatsen je comments kwijt.
- MDFs kunnen goed omgaan met schema drift, dus wegvallende en nieuwe kolommen ten opzichte van een eerder vastgesteld schema. Dit maakt MDFs een stuk robuuster dan bijvoorbeeld SQL-processing als je schema-less data verwerkt (lees: files uit data lakes) waar het schema niet gegarandeerd is.
- Dataflows zijn te editen in ‘script’ viewer, dus code-based i.t.t. de visuele interface. Dat kan enorm handig zijn, maar let op: die editor is foutgevoelig, één teken mis, of een witregel halverwege het script en je hele dataflow kan wegvallen – en er is geen ‘back’ knopje ?.
MDFs en Structured databases
SQL Databases worden al lang gebruikt als datawarehouse om gegevens historisch op te slaan en beschikbaar te stellen voor analyse en rapportages. Er zijn veel manieren om data naar en door een datawarehouse te leiden en MDFs is er daar één van.
MDFs werken heel goed samen met bijvoorbeeld Synapse Dedicated SQL pools. Brontabellen zijn gemakkelijk toe te voegen in een MDF als source en target, en kolom mappings worden automatisch toegevoegd. Ook zijn er veel MDF templates in Azure Data Factory te vinden, bijvoorbeeld voor het vullen van type 2 dimensie tabellen. Die templates laten ook de kracht zien om via data factory flow control activities MDFs te parametriseren, zodat je alleen nog maar wat configuratie data nodig hebt om met één MDF alle dimensie tabellen in een data mart te vullen.
Een andere manier om gelaagdheid in de dataprocessing door MDFs aan te brengen zijn flowlets, vergelijkbaar met user defined functions: gecentraliseerde en herbruikbare maatwerk functies zoals het toetsen van emails aan een regex, opschonen van strings, geocoding, etcetera.
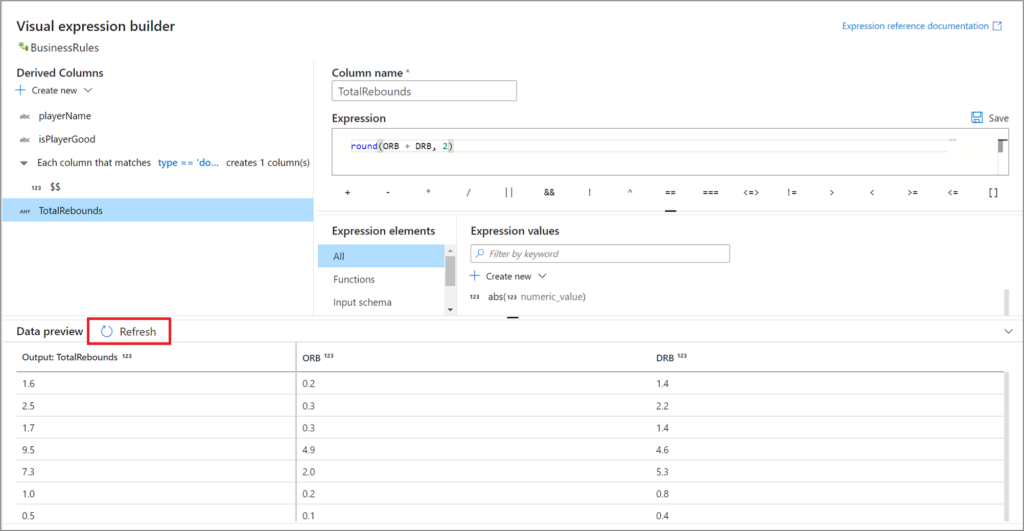
Tenslotte is ook de debug / data preview modus een mooie functie waarmee je inzicht kan krijgen in de ‘data tussenproducten’ per transformatie. Het is hierdoor veel makkelijker om onverwachte resultaten te debuggen, en, afhankelijk van persoonlijke smaak en vaardigheden, kan dit ook een voordeel zijn t.o.v. het debuggen van stored procedures in een SQL Database.
Let wel op: In de debug settings van een MDF kan je aangeven hoeveel rijen per bron gesampled worden voor de ‘Preview data’ activiteiten. In grote MDFs, zeker later in de pipeline als er filters van toepassing zijn, zal het vaak zo zijn dat in ‘Preview data’ geen resultaten getoond worden. Dan zit er weinig anders op om een kleine test MDF op te tuigen voor de operatie die je wil toepassen.
MDFs en Data lake(house)s
Een relatief nieuwe data platform architectuur is die van het Data Lake House. Voor een uitgebreide review van die architectuur kan James Serra je op weg helpen. In een notendop gaat het om een data platform dat alle persistente data in een data lake plaatst, en daar een virtuele SQL laag overheen legt. Deze architectuur is met moderne technologie zoals Databricks, Delta Lake en Synapse Serverless erg mooi te implementeren. Mapping Dataflows passen prima in die architectuur als de primaire tool om data door de keten voort te brengen.
Spark: een ‘federated technologie’
MDFs draaien op een Spark engine. Spark verdeelt data operaties over een veelheid aan ‘workers’, en die opzet is wezenlijk anders dan single SQL database verwerking. De technologie is meer vergelijkbaar met Massively Parallel Processing (MPP) data warehouses zoals Synapse SQL pools of Snowflake. Hieronder een aantal tips & tricks gerelateerd aan deze Spark engine:
- Denk goed na over data partitioning bij het verwerken in Spark, en over het wegschrijven van data naar SQL Clustered Columnstore Indexes. Een optimale verdeling van data ‘brokken’ over de workers, en goede kwaliteit van Rowgroups, wordt vaak vergeten.
- Non-equi joins (dus een join met een ‘voorwaarde’ zoals groter dan, kleiner dan) vereisen dat tenminste één dataset van de join volledig in-memory wordt genomen voor alle workers. Dat kan veel overhead veroorzaken. Het is vaak handiger om de voorwaarde voor te bereiden met een derived column (bijvoorbeeld if-then-else over de verschillende voorwaarde ranges resulterend in een integer waarde) en dan een equi joi op basis van die integer te hanteren.
- De opstart van Spark clusters leidt tot wachttijd en daarmee verminderde flow in Development werk: start-up van een cluster kost tijd, ook in debug mode. Als je de Time To Live wat langer instelt kan je je debug cluster wel vaak ‘hergebruiken’. Let op dat je ‘Interactive Authoring’ op de Integration Runtime aan hebt staan, anders moet je ook daar op wachten (bv voor ‘Preview content’, ‘Browse folders’ etc.).
- Als je de resultaten van een MDF die zijn weggeschreven als file (Parquet, Delta) diepgaand wil analyseren, dan is een SQL omgeving vaak de tool van keuze. Je hebt veel opties tot je beschikking om dat voor elkaar te krijgen. Onze ervaring is dat Synapse Analytics de beste optie is om met de OPENROWSET functie queries te draaien op data die is vastgelegd in bestanden. Het grote voordeel hiervan is namelijk dat het zeer performant is en dat je het kunt draaien zonder opstarttijd.
Concurrency issues op snijvlak MDFs, Synapse Spark en Delta files
- In een sink van type Delta file kan je Delta Options aanvinken. Dit zijn veelal ‘Post commit’ activiteiten (bijvoorbeeld auto-compact). Let op dat deze acties ‘na-ijlen’! Dus wanneer je pipeline afgerond is, ondergaat de Delta file nog steeds operaties en is hij niet direct beschikbaar voor een volgende flow. Een wait step van 60 seconden lost dit op.
- Als je een bestaande MDF en de gerelateerde Delta files flink omgooit, dan kunnen diverse issues opspelen. Denk bijvoorbeeld aan een delta folder die als sink wél data geeft in preview, maar als source niet, of aan een situatie dat een MDF goed loopt maar de doelmap leeg blijft. Dit lijkt gerelateerd te zijn aan de Hive Metastore die niet meer de meest recente definities heeft van de objecten in de MDF. Een reboot van je (debug) Spark cluster doet vaak wonderen!
- In meer exotisch gebruik kan je in MDF’s ‘loopen’ over hetzelfde delta file, dus één Delta file als sink én ook als source. Dit kan bijvoorbeeld zinvol zijn om een bestaand master-data object te verrijken met aanvullende kenmerken uit een nieuwe bronnen. Die aanpak geeft geen validatie error maar werkt niet zoals je wellicht verwacht: de doelmap blijft leeg. Als je een ‘Alter Row’ transformatie stap toevoegd, en de settings daarvan goed afstemd met de settings in je sink, dan werkt het wél.
Concluderend
Het is duidelijk dat Microsoft flink gas geeft op Mapping Dataflows als serieuze tool in de Synapse Analytics omgeving. Met grote snelheid worden nieuwe features toegevoegd, zoals de eerdergenoemde flowets. Ook de flink verminderde wachttijd bij het aanzetten van een debug cluster is een flinke verbetering: in ADF MDFs binnen 10 seconden sinds maart 2022, en dit zal ook snel naar Synapse komen verwachten we.
Nu al top is de performance: zeer aansprekend omdat er gebruik gemaakt wordt van de Spark processing engine. Bovendien is de visuele UI erg toegankelijk en via een browser overal beschikbaar. Ook kennen MDFs een rijke Expression Language, inclusief een set (statistische) functies t.b.v. dataprocessing, die veel rijker is dan native functies in de meeste SQL-engines.
Kortom (TLDR), Mapping Dataflows zijn een mooie aanvulling op de toolset van een data engineer! SQL first (ADF en store procedures, bijvoorbeeld) heeft ook voordelen, zoals kort-cyclisch debuggen en sommige van onze consultants zijn productiever met SQL. Dus of MDFs bij elke organisatie past? Dat gesprek gaan we graag met je aan, wat denk jij?