De drie belangrijkste overwegingen bij het kiezen van je Fabric datastore
Een nieuw data platform, cool! Maar hoe gaan we de data opslaan? Als één van de eerste stappen in het opzetten van een dataplatform gaan we bepalen welke technologie we gaan gebruiken voor data-opslag. Zelfs binnen Fabric is er nog een scala aan mogelijkheden: een Lakehouse, Warehouse, Eventhouse, SQL Database of gewoon een Power BI datamart.
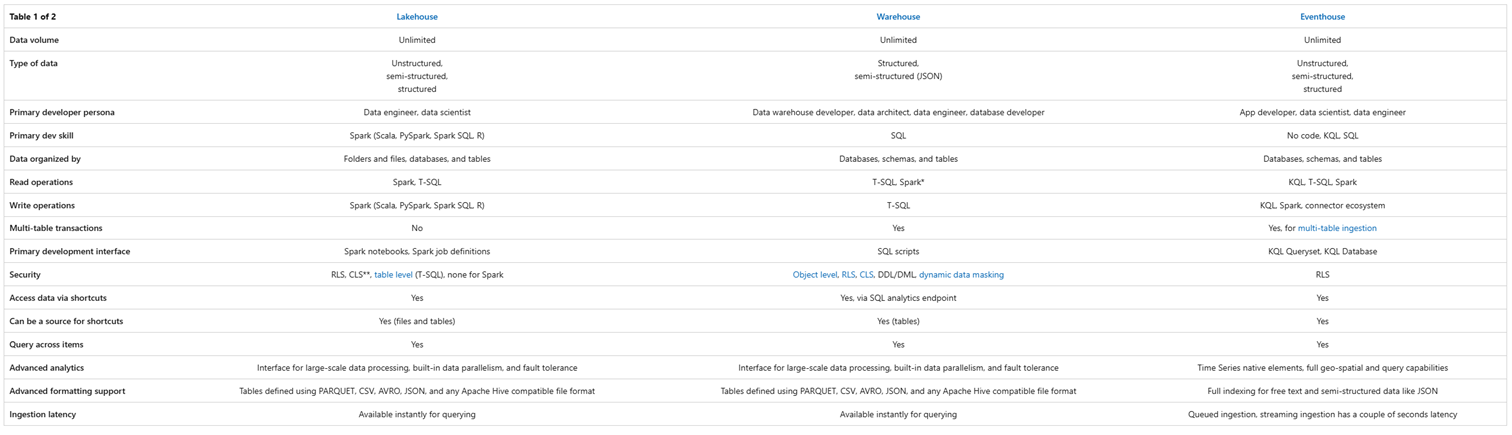
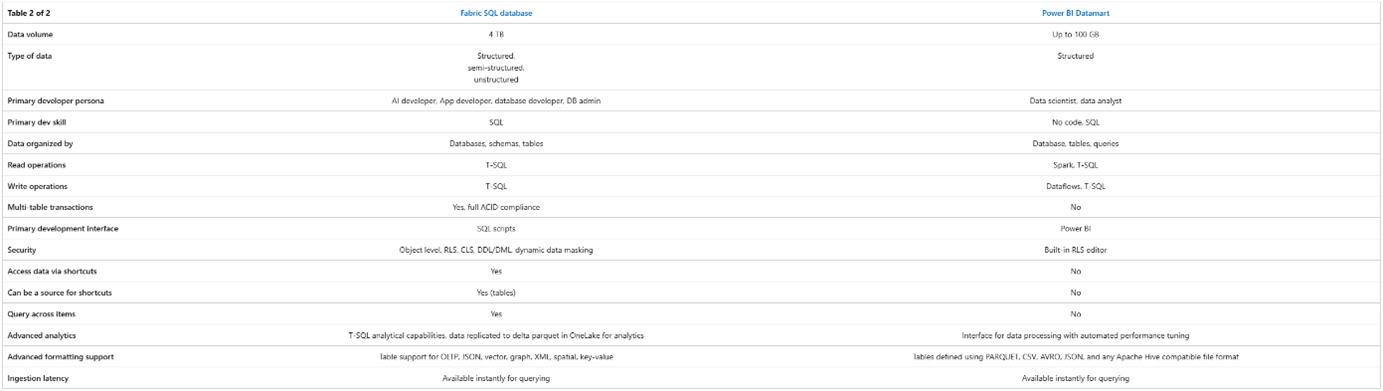
Hierbij is het uitgangspunt dat we een dataplatform aan het maken zijn, binnen Fabric, dus kunnen we meestal drie opties direct wegstrepen:
- SQL Database – deze is primair bedoeld als OLTP oplossing en is niet geoptimaliseerd voor OLAP gebruik. Dit geeft leuke mogelijkheden met bijvoorbeeld het monitoren van actuele loadstatus van je objecten, maar omdat je meeste data in bulk zal worden behandeld, zal je dit eerder inzetten voor een applicatie dan voor een dataplatform.
- Eventhouse – we zien hier steeds meer mogelijkheden ontstaan, maar momenteel is het voornamelijk een oplossing voor streaming data. Handig om toe te voegen aan een bestaand platform om, parallel aan de hoofdstroom, nieuwe mogelijkheden te hebben, maar vormt niet zomaar de backbone van je platform. Voor event logs is het ook een interessante optie, zoals in de ingebouwde optie van Fabric voor workspace monitoring.
- Power BI Datamart – nog altijd in preview en onze minst favoriete datastore. In specifieke situaties zou het een mogelijke vervanging van een dataplatform moeten vormen, of een oplossing die erbovenop wordt gebouwd. Dit is geen optie die wij adviseren.
Daarmee is de kans groot dat de uiteindelijk keuze zal gaan tussen Lakehouse en Warehouse. Dan begint de discussie pas echt! Wij adviseren om de volgende drie facetten goed tegen het licht te houden:
Bestaande code en platform
Zelden begin je aan het ontwerp in een volledig vacuüm. Meestal is er al een deel aanwezig, of een vorige versie van een dataplatform. Zeker tijdens een ontwerpfase is de verleiding groot om alle oude code ongezien weg te gooien, maar daarmee verlies je ook alle verzamelde kennis, alle gevonden uitzonderingen en alle obscure business logica. Refactoren en herstructureren is nuttig, maar koppel dit niet aan een migratie – doe het ervoor of erna.
Daarom is het cruciaal te kijken naar wat goed aansluit bij je bestaande platform. Heb je al veel code in Python staan? De stap naar Notebooks in een Lakehouse is kleiner. Verwerk je je data momenteel vooral met T-SQL? Dan is het toch logischer naar een Warehouse te kijken.
Het team
Ook al lijkt het alsof je kiest een technische oplossing, of op basis van het directe prijskaartje, de mensen in je team(s) zullen er uiteindelijk mee moeten werken. Zij bepalen de kwaliteit van je oplossing en daarmee de stabiliteit van wat er staat en de snelheid van wat erbij kan worden ontwikkeld. Het is dus belangrijk in je overweging mee te nemen waar je huidige team het meest ervaren in is, of waar je het makkelijkste goede mensen voor kunt rekruteren.
Zelfs als er nog geen specifieke ervaring aanwezig is met een taal, kan je inschatten waar mensen effectiever in werken. We zien dat mensen die meer ervaring en feeling met code hebben, makkelijker zich de denkwijze van een Lakehouse aanleren. Mensen die veel ervaring met oudere BI tooling hebben zullen zich sneller thuisvoelen in een Warehouse.
Technische features
Uiteindelijk ontlopen de mogelijkheden van beide data stores elkaar niet zoveel. Als puntje bij paaltje komt kunnen beide werken met SQL, lezen met Spark, opslaan in Delta Parquet, en zo verder.
Een belangrijk verschil volgens Microsoft is de mogelijkheid tot multi-table transactions – een indrukwekkende feature voor data-integriteit. Enkel een Warehouse ondersteunt dit, dus als je het nodig hebt, is het een bepalende factor. Wij zijn dit echter nog niet als eis tegengekomen en het kost moeite scenario’s te bedenken waar dit cruciaal is. Daarentegen zien wij als belangrijkste bepalende feature de shortcuts – de mogelijkheid om andere cloud- en OneLake-bronnen aan te sluiten zonder deze over te laden. Dit is een nieuwe mogelijkheid die Onelake heeft gebracht en alleen met een Lakehouse kan je hier gebruik van maken.
Ook voorziet alleen een Lakehouse in een files-map, waarin je inkomende bestanden in hun oorspronkelijke formaat kunt plaatsen. Dit is onmisbaar als je een Fabric-only architectuur wilt maken, met een historische bronslaag. Zonder het Lakehouse is hier ofwel een niet-Fabric opslag voor nodig, of kan alleen verder verwerkte data worden opgeslagen.
Vervolgstappen
Na een keuze op grote lijnen is het nuttig om door de details van zowel de gewenste als de geboden specificaties te lopen met vragen als:
- Hebben we aan alle soorten data gedacht?
- Zijn onze use cases afgedekt?
- Welke integratiemogelijkheden gaan we gebruiken?
- Hoe werkt dit met licenties en security?
Misschien dat er ergens nog een addertje onder het gras schuilt, wat je dwingt terug naar de tekentafel te gaan. Indien mogelijk kan je een proof of concept starten, zodat je nog meer zekerheid hebt over hoe elke stap werkt. Na de keuze van je opslag sta je nog aan het begin van een serie volgende keuzes. Gebruiken we een enkele data store voor alle layers, of verdelen we de layers over meerdere data stores? De eerste optie is simpeler te overzien en op te zetten, bij de tweede optie kan je een andere keuze maken per store. Met welke tools ga je elke laag inrichten? Hoe beheer je de OTAP-straat? Hoe ga je om met gevoelige data? Hoe verspreid je data na verwerking? Hoe richt je data management in?
Ik ben benieuwd met welke vragen je worstelt, neem vooral contact op als we met je mee kunnen denken!
Naast de bovengenoemde overwegingen kun je als referentie ook gebruik maken van de Microsoft’s eigen Decision Guide met een paar verhelderende tabellen.