


A Metadata Driven Framework for MS Fabric: What is it and why do you want it? – Part 1
What is a metadata-driven framework in a data platform?
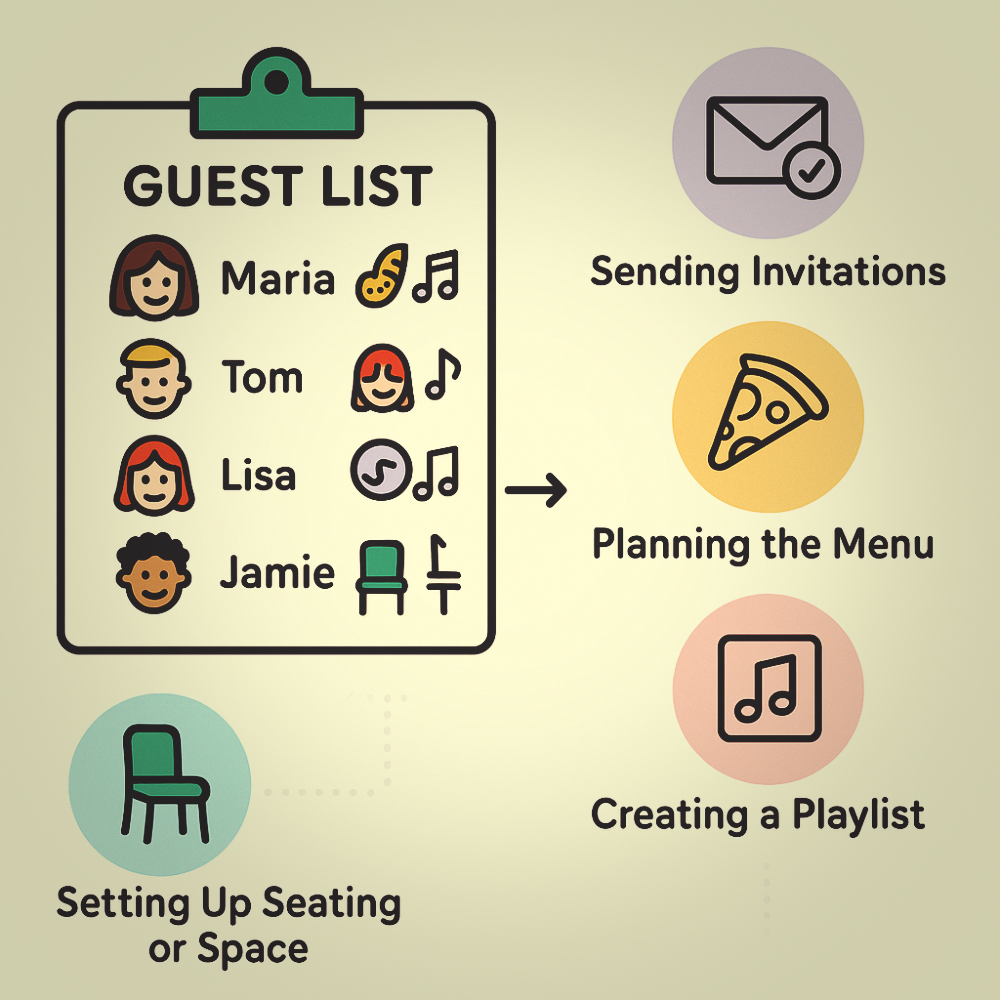
Imagine you’re throwing a party. Instead of just randomly inviting people, you create a guest list that specifies who to invite, what they like to eat, and what music they enjoy. This guest list helps you plan everything smoothly, ensuring that you have enough snacks for your friends who love chips and the right playlist for those who can’t resist dancing. You use the list as input for the actions you need to do, such as shopping (what to shop for) or creating playlists (what music to select).
In a similar way, a metadata framework in a data platform serves as a guide for processing data. It enables an architecture that uses generic procedures relying on lists as input. These lists define what to process and how, and they are referred to as “metadata” because they contain data about the data to be processed.
A conceptual example in MS Fabric
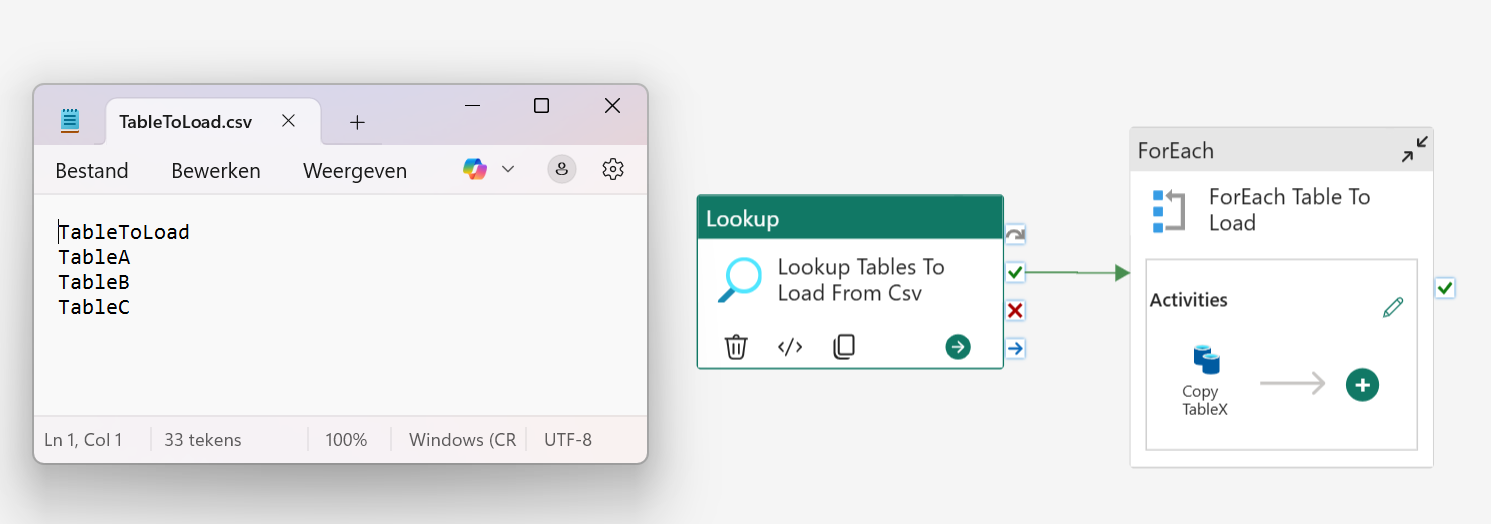
Let’s assume we want to load 3 tables from an on-prem sql database to our Lakehouse landing zone in Fabric.
Option 1: non-metadata driven
Use a pipeline with 3 copy activities, each set to copy a specific table (CopyTableA, CopyTableB, CopyTableC).

Option 2: metadata-driven
Create a csv view file “TablesToLoad.csv” with 3 lines: TableA, TableB, TableC Create a pipeline with a ForEach activity and one Copy Activity. The ForEach is set to the output of a Lookup activity reading from the csv file.
Pros of a Metadata-Driven Approach
A metadata framework is especially powerful when dealing with many similar actions. Loading 3 tables with individual copy activities? Fine. A hundred? That’s a maintenance nightmare. That’s where metadata shines. In the second option, adding table names to a CSV is all it takes, while the first approach would require 97 additional copy activities.
Metadata can also drive smarter logic. For instance, adding an IsIncremental column lets you control load behavior (incremental vs. full) per table.
This approach scales well across layers—Bronze, Silver, etc.—by using separate metadata files or tables to define what to load, when to refresh, apply transformations, manage data types, or rename columns. All of this helps centralize and organize logic.
Instead of CSVs, metadata can be stored in database tables, enabling easy querying, auditing, and reporting—far more efficient than scanning code.
When It Doesn’t Work
A metadata-driven approach works best when actions are repetitive and standardized. If your processes involve many one-off variations, forcing them into a metadata framework can add unnecessary complexity and reduce flexibility.
A strong framework should allow hybrid solutions, clearly separating what is metadata-driven and what isn’t, based on best practices.
Parameterized vs. Generated Code
Finally, let’s look at two common approaches in metadata-driven development: parameterized code and generated code.
Parameterized Code
In this approach, metadata is used as input parameters within the code. The same code runs across all cases, and its behavior changes dynamically based on the metadata. If the metadata changes, no new code is needed—the existing logic adapts automatically.
For example, in option 2, if you add Table4 to the CSV file, the same code will pick it up and copy the table without requiring any changes to the code itself.
Generated Code
This approach involves automatically generating code based on the metadata. When the metadata changes, the code must be regenerated to reflect those updates.
For instance, in option 1, the code can be generated by a tool using the metadata. If Table4 is added to the CSV file after code generation, it won’t be included until the tool regenerates the code and you deploy it again.
More Metadata-Driven Context
For more details on this whole metadata-driven idea, check out the great overview by Ishan Shrivastava in this article. If you want to dive deeper, there’s also a detailed article on the specifications for a Lakehouse metadata-driven solution in the Metadata-Driven Lakehouse Playbook.
Conclusion
A metadata-driven approach offers many advantages and is definitely worth considering when implementing a new data platform. However, it’s important to carefully evaluate how extensively you want to apply metadata and which parts of the platform will benefit most. A thoughtful analysis upfront can help strike the right balance between flexibility, complexity, and maintainability.
Next Steps: Open-Source Solutions
When building a data platform, much of the required logic tends to be fairly standard—especially when following a common architecture such as the medallion layer approach (bronze, silver, gold) or similar layered designs (like landing, cleaned, curated). These patterns create opportunities to reuse existing frameworks and solutions rather than reinventing the wheel.
In the next article, I’ll explore the benefits of using open-source solutions and take a look at what’s currently available—or on the horizon—for Microsoft Fabric.
Have you worked with any open-source frameworks for data platforms? Or are you aware of interesting existing or upcoming solutions for Microsoft Fabric? 👉 Feel free to share them—I’d love to include your input!